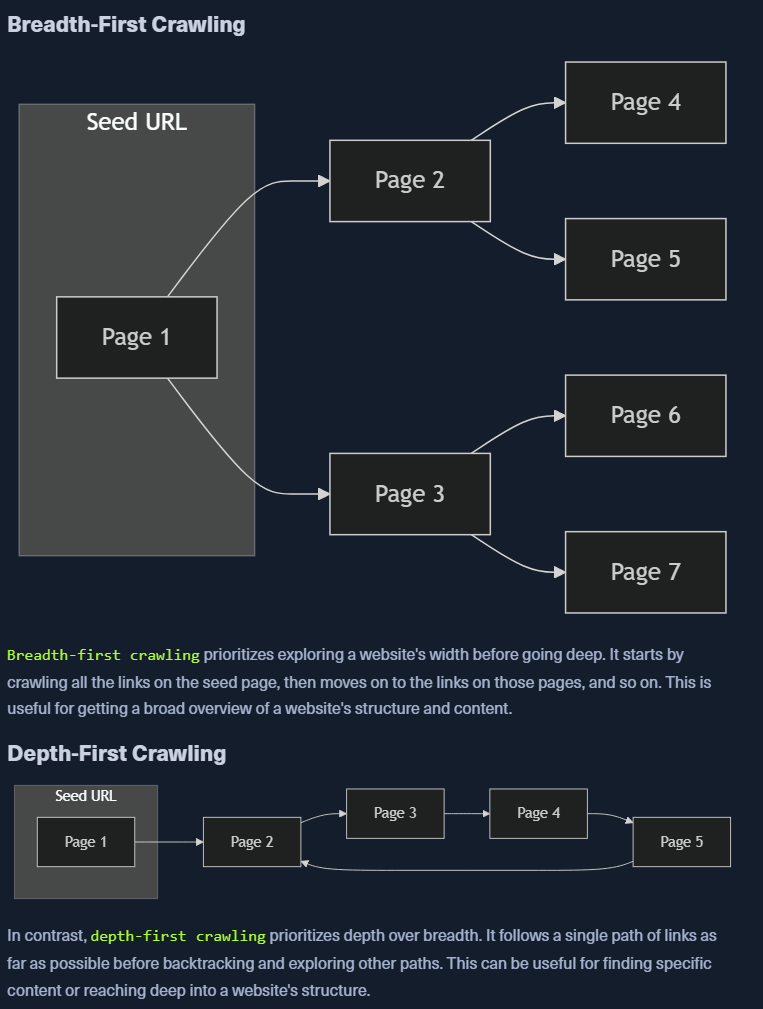
Crawling + robots + Well known URIs
- Spidering is the automated process of systematically browsing the WWW
- follows links from one page to another
- bots with pre-defined algos to discover and index web pages for web recon and data analysis
You might find: 1. Links 2. Comments 3. Metadata 4. Sensitive files
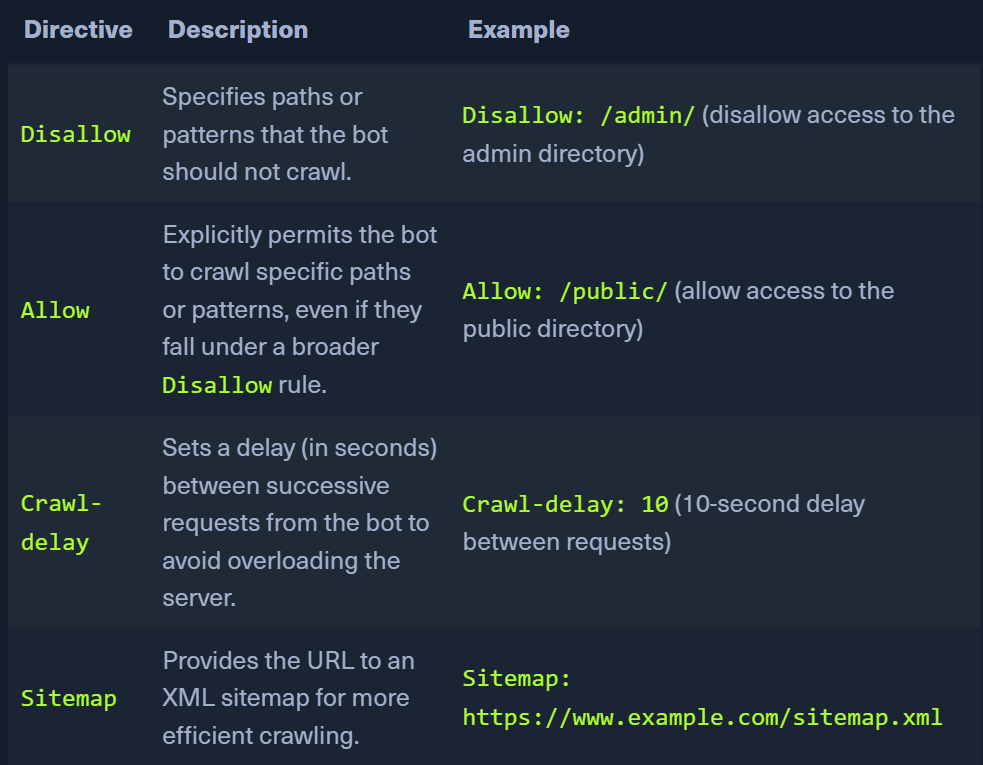
robots.txt
- tells bots which websites can and cannot be crawled
- Can find hidden directories, map website structure, detect crawler traps
- robots.txt is a file in the root directory.
User-agent: *Directives- Why follow robots.txt:

Well-Known URIs:
- The
/.well-known/path in the root domain of the website contains config files related to services, protocols and security mechanisms - IANA registry of
.well-knownURIs - https://www.iana.org/assignments/well-known-uris/well-known-uris.xhtml 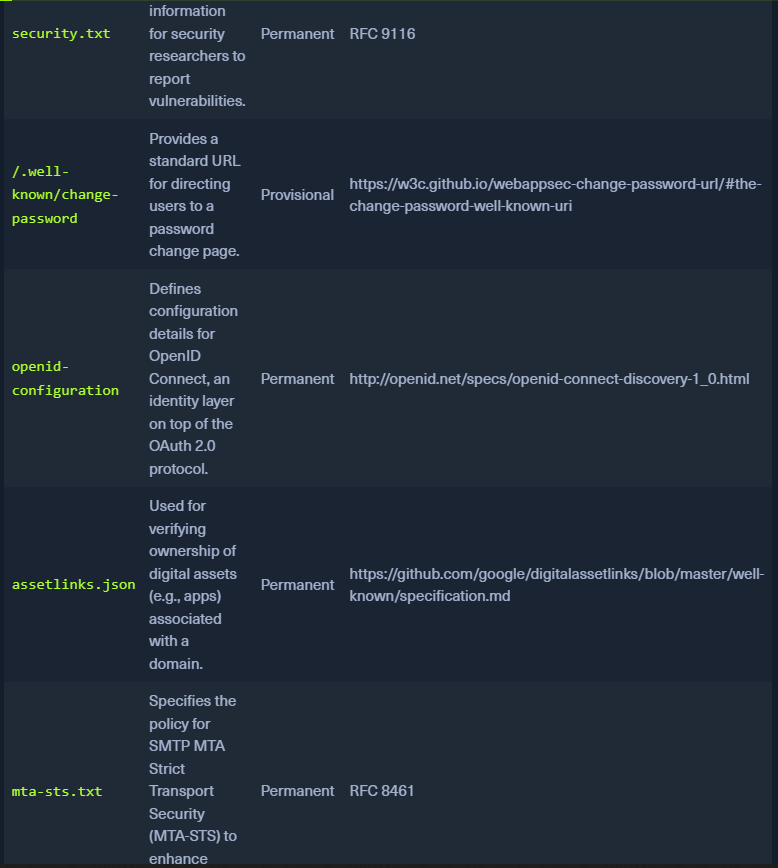
openid-configurationendpoint will return a JSON doc
Tools:
- Burp Spider
- OWASP Zap
- Scrapy
-
Apache Nutch
-
sudo python3 ReconSpider.py http://inlanefreight.com